StringPool(字符串常量池)
字符串常量池的解释
字符串常量池(String Pool)保存着所有字符串字面量(literal strings),这些字面量在编译时期就确定哪些是要放入字符串常量池。具体来说,只有使用双引号("")创建的字符串字面量才会被认为是常量,从而被放入常量池中。
在运行时,还可以使用 String 的 intern() 方法在运行过程将字符串添加到 String Pool 中。调用该方法会判断字符串常量池是否有该字面量,如没有,会在字符串常量池创建。之后,会返回字符串常量池中的对象。
通过new创建的字符串字面量,会先将,无论是否在字符串常量池存在,都会创建新的对象且不放入字符串常量池。
String str1 = "Hello world!";
String str2 = "Hello world!";
String str3 = new String("Hello world!");
String str4 = new String("Hello world!");
String str5 = str4.intern();//运行过程中把字符串添加到String Pool,并返回String Pool中的对象
System.out.println(str1 == str2);//运行结果:true。
System.out.println(str1 == str3);//运行结果:false。
System.out.println(str3 == str4);//运行结果:false。
System.out.println(str1 == str5);//运行结果:true。
System.out.println(str4 == str5);//运行结果:false。
字符串常量池长度
- 在 jdk6中,StringTable的长度是固定的,就是1009的长度。所以如果常量池中的字符串过多,会产生hash冲突,导致链表变长,降低查询效率。
- 在jdk7中,StringTable的长度可以通过一个参数指定:
-XX:StringTableSize=99991
字符串常量池的位置
不同版本的Java虚拟机(JVM)可能会采用不同的方式来实现字符串常量池,并且在不同的JVM实现中,字符串常量池的位置也可能会发生变化。
-
JDK 6
字符串常量池存在于运行时常量池,运行时常量池存在方法区。方法区的实现为永久代(PermGen)。
PermGen默认大小只有4m,这种设计可能会导致PermGen空间溢出(java.lang.OutOfMemoryError: PermGen space)的问题,并且在频繁加载大量类文件时容易出现性能问题。 -
JDK 7
为了解决这些问题,从 JDK 7 开始,字符串常量池被移动到了堆内存中。 -
JDK 8
还是在堆内存中。
字符串的拼接
如果定义字符串时有拼接的表达式,编译器会根据表达式的参数是否为""直接引用来判断是否将字符串字面量放入字符串常量池。
如表达式"Hello"+" world!",编译器会将两个字符串拼接成一个新的字符串"Hello world!",然后对比这个新字符串对象和常量池中的字符串字面量"Hello world!"是否相同。由于Java字符串常量池的特性,当两个字符串的内容相同时,它们所引用的字符串对象实例也是相同的。因此,表达式"Hello"+" world!" == "Hello world!"的结果为true。
如表达式str1 + str2,尽管变量拼接后的内容与常量池中的字符串字面量"Hello world!"相同,但是由于在编译期间无法确定变量str3的值,因此实际上等价于在运行时通过new操作符创建了一个新的字符串对象,与常量池中的字符串字面量不同。因此,表达式str3 == "Hello world!"的结果为false。
String str1 = "Hello";
String str2 = " world!";
String str3 = str1 + str2;
String str4 = "Hello"+" world!";
System.out.println(str3 == "Hello world!"); // false
System.out.println(str4 == "Hello world!"); // true
intern
intern 方法会从字符串常量池中查询当前字符串是否存在,若不存在就会将当前字符串放入常量池中。
实现
openjdk7/hotspot/src/share/vm/classfile/symbolTable.cpp
oop StringTable::intern(Handle string_or_null, jchar* name, int len, TRAPS) {
unsigned int hashValue = java_lang_String::hash_string(name, len);
int index = the_table()->hash_to_index(hashValue);
oop string = the_table()->lookup(index, name, len, hashValue);
// Found
if (string != NULL) return string;
// Otherwise, add to symbol to table
return the_table()->basic_add(index, string_or_null, name, len, hashValue, CHECK_NULL);
}
大体实现结构就是: JAVA 使用 jni 调用c++实现的StringTable的intern方法。StringTable的intern方法跟Java中的HashMap的实现很像。可以说StringTable是String Pool的实现,或者笼统说StringTable=String Pool。
不同版本JDK的intern
public static void main(String[] args) {
String s = new String("1");
s.intern();
String s2 = "1";
System.out.println(s == s2);
String s3 = new String("1") + new String("1");
s3.intern();
String s4 = "11";
System.out.println(s3 == s4);
}
执行结果:
- JDK6:false false
- JDK7:false true
分析
-
JDK6
JDK6中的常量池是放在 Perm 区中的,Perm 区和正常的 JAVA Heap 区域是完全分开的。如果是使用引号声明的字符串都是会直接在字符串常量池中生成,而 new 出来的 String 对象是放在 JAVA Heap 区域。因为存在区域不同,导致内存地址不同。所以intern在JDK6无法重用字符串常量池缓存的对象。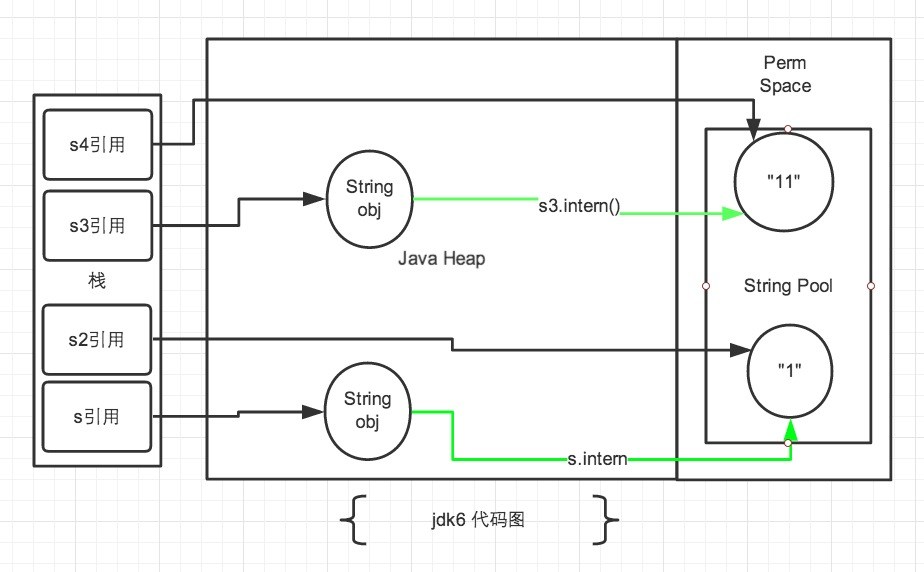
-
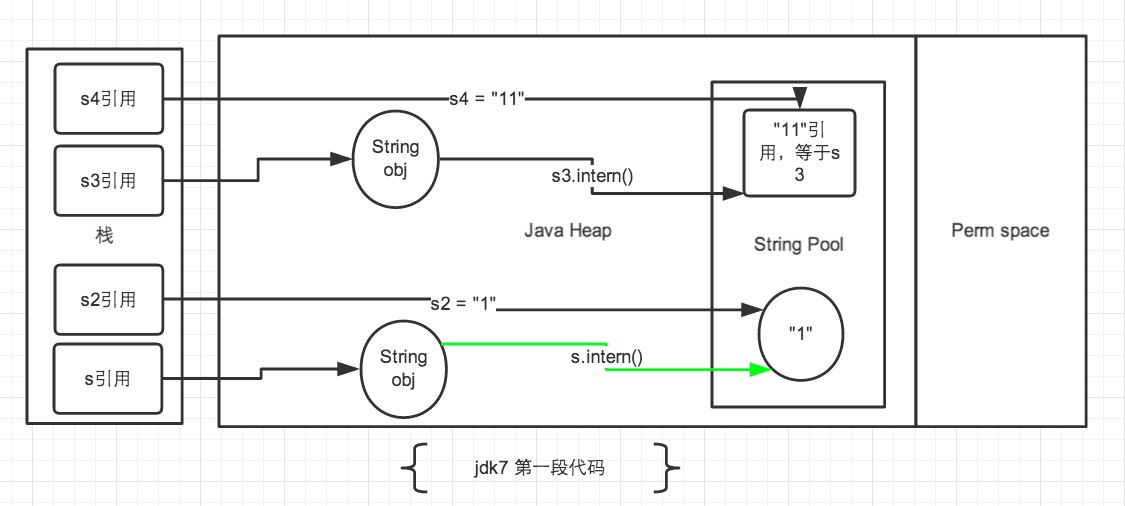
JDK7
- s和s1部分。对象s如[[07题#String str =new String(“ab”) 会创建几个对象?]]。此时s.intern();查询发现字符串常量池已经有字符串了。s2因为是加了引号,编译期就确定了要存字符串常量池,因为字符串常量池已经有了相同字面量的对象,所以直接复用。
- s3和s4部分。对象s3如[[07题#String str =new String(“a”) + new String(“b”) 会创建几个对象 ?]]。此时创建了多个对象,其中“ab”对象在普通的堆内存中。使用s3.intern();将"ab"引用地址复制到字符串常量池。
使用案例
intern适合会频繁复用字符串的场景。如:
int MAX = 1000 * 10000;
String[] arr = new String[MAX];
Integer[] DB_DATA = new Integer[10];
Random random = new Random(10 * 10000);
for (int i = 0; i < DB_DATA.length; i++) {
DB_DATA[i] = random.nextInt();
}
long t = System.currentTimeMillis();
for (int i = 0; i < MAX; i++) {
//创建大量重复对象可以使用intern来复用字符串常量池
arr[i] = String.valueOf(DB_DATA[i % DB_DATA.length]).intern();
}
System.out.println((System.currentTimeMillis() - t) + "ms");
System.gc();
参考: