Java8一个汉字占几个字节
总结
不同的编码格式占字节数是不同的,UTF-8编码下一个中文所占字节大多常用字是3个字节、少部分是4个字节。UTF-16编码下一个中文所占用字节大多常用字是2个字节,少部分是4字节。
Java存储字节码使用UTF-8节省处理字符串所占用,运行使用UTF-16节省处理字符串时间。
名词解释
- 字节:byte
- 字符:char
- code unit:编码中最小单位,UTF-8中为1字节;UTF-16中为2字节。
- code point:Unicode字符集中所对应的唯一编号,即一个文字的唯一编号。
- 内码(internal encoding):程序内部使用的字符编码,特别是某种语言实现其char或String类型在内存里用的内部编码。
- 外码(external encoding):程序与外部交互时外部使用的字符编码。“外部”相对“内部”而言;不是char或String在内存里用的内部编码的地方都可以认为是“外部”。例如,外部可以是序列化之后的char或String,或者外部的文件、命令行参数之类的。
编码格式
- ASCII 码
128个 - ISO-8859-1
256个 - GB2312
6763个汉字 - GBK
兼容GB2312,能表示2W+汉字 - GB18030
使用不广泛 - UTF-16
Unicode(Universal Code 统一码):定义文字编码
UTF:定义Unicode在计算机中的转换。
UTF-16:设计之初是定长2个字节,后面变为可变长2|4字节。一个字符(char)用两个字节表示,简化字符串转换操作,提高效率。 - UTF-8
采用了一种变长技术,每个编码区域有不同的字码长度。不同类型的字符可以是由 1~6 个字节组成。
编码对应关系
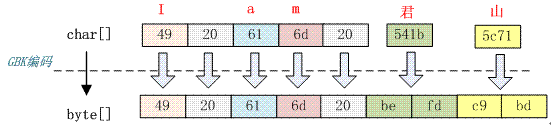
GBK编码
英语字母等需要1个字节,1个汉字对应2个字节。
UTF-16 编码
code unit为2个字节,英语字母等需要2个字节,中文需要2|4字节。

UTF-8 编码
code unit为1个字节,英文等字母需要一个字节,中文变为3|4个字节。

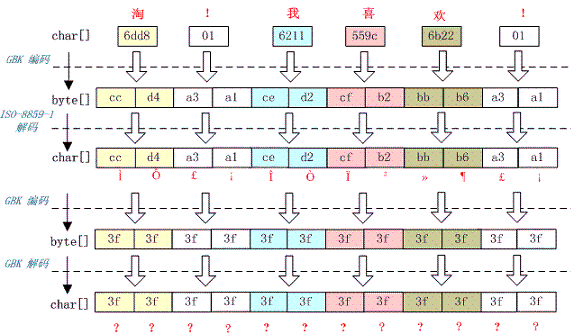
乱码
中文变成了看不懂的字符
例如,字符串“淘!我喜欢!”变成了“Ì Ô £ ¡Î Ò Ï²»¶ £ ¡”。
I/O输出方字符串采用GBK编码成字节数组,I/O接收方收到后对其用ISO-8859-1节码。模拟代码如下。
String str = "淘!我喜欢!";
byte[] gbkBytes = str.getBytes("GBK");
String isoStr = new String(gbkBytes, "ISO-8859-1");
System.out.println(isoStr);
编码过程如下图所示。

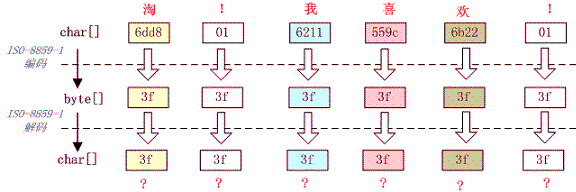
一个汉字变成一个问号
例如,字符串“淘!我喜欢!”变成了“??????”。
I/O输出方字符串采用ISO-8859-1编码成字节数组,I/O接收方收到后对其用ISO-8859-1解码。模拟代码如下。
String str = "淘!我喜欢!";
byte[] isoBytes = str.getBytes("ISO-8859-1");
String isoStr = new String(isoBytes, "ISO-8859-1");
System.out.println(isoStr);
编码过程如下图所示。
一个汉字变成两个问号
例如,字符串“淘!我喜欢!”变成了“????????????”编码过程如下图所示。
SpringBoot中的乱码
application.properties乱码
参考
原因
application.properties文件使用ISO-8859-1解码。
CharacterReader(Resource resource) throws IOException {
this.reader = new LineNumberReader(
new InputStreamReader(resource.getInputStream(), StandardCharsets.ISO_8859_1));
}
解决办法
- @PropertySource(value = "classpath:非application.properties", encoding = "UTF-8")
- 使用yml或者ymal
- IDE/插件预编码,没试过
-
- 在 SpringBoot 项目中设置
spring.factory的org.springframework.boot.env.PropertySourceLoader,指定自定义的 PropertySourceLoader, 自定义处理。没试过。
- 在 SpringBoot 项目中设置
参考:
License:
CC BY 4.0